Git & GitHub For Humans (Part 1)
- 5 mins 
To understand the use/need of git, let consider an example.
Imagine yourself as a writer, working on the draft of your next best-seller. You have decided that your novel would be about the life journey of an orphaned and ill-treated kid, as he discovers his gift of magical powers, fights an evil wizard who is also the murderer of his family and eventually wins. Originality ;)
In this modern era, it is highly unlikely that you would create such a draft with pen and paper, use of a computer software like Microsoft Word, is almost guaranteed. Half way through your draft, suppose you felt that the beginning of the story was not good enough, and you should rewrite it. What would you do? Would you overwrite the draft document? What if the new beginning was worse? You definitely would want to try different beginnings to your story while still keeping it possible to go back, if ever felt required. So basically any writer would want to preserve not only the current state of the draft but also the history of it. One way to achieve this would be to just create copies (snapshot) of the draft document at different instances of time. So before you rewrite the beginning of your story, you would create a copy of the draft at that moment in time. So, if you screwed up in the future, you could always go back to this copy of your draft. More often than not if you are working on a big project, what you would end up with would look something like this -
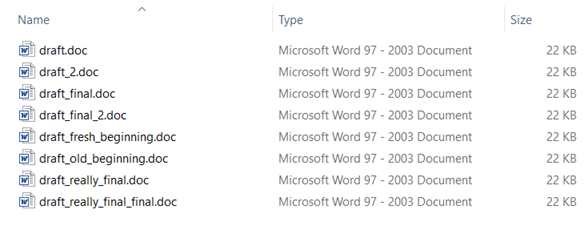
As you can probably guess, this method of “version control” clearly sucks. If you still can’t get why it’s so bad -
-
There is no easy and elegant way to relate a copy of the draft (snapshot) with the instance of time it was made. There is a limit to what can be written in a filename.
-
Everything has to be done manually, which is tedious as well as prone to human error. What if you forgot to save a copy? or you mistakenly edited a snapshot?
-
What if the project you are working on has multiple files, you may have to clone all files for all instances?
-
High memory consumption, say you have 100 snapshots of your 25 megabyte draft, the whole thing would require approximately a memory space of 100 x 25 MB = 2.5 GB.
Now suppose, your novel eventually makes it to the top and now a major film studio wants to make an adaptation of your work. The film studio approaches you with the deal on a condition — that you would work with another well-known writer, to rewrite portions of the story, to adapt it for a film. You, after fair amount of discussion agree to their demand.
You and other writer decide to store the draft on a server, where it can be accessed by both of you and you both made local copies of the draft for editing purpose. You both are of the opinion that the end fight scene would require a fair amount of work, so you both divide the work — you decide to work on the portion leading up to the end fight scene, while your peer decides to work on the end fight scene itself. You both definitely would not work in isolation — lot of communication during the rewriting process is expected. You both would want to review each other’s work. To share your changes with your peer, you would have upload it to the server.
Suppose during the rewriting period, you feel that the portion leading up to final fight must be more emotional, the sorrow and loss of the protagonist must be felt by the audience. You reckon that killing the protagonist’s love by the hands of the evil wizard, is the right way to go about it. You add that extra scene in your copy of the draft, which details the murder of the protagonist’s love. Now you want to save that changes on to main draft stored on the server. What would be the right way of doing it? Would you just replace the main draft document (on the server) with your (local) copy of the draft document? That would be okay if you were working alone, what if after the instance you made a local copy of the draft, your colleague made changes in the main draft — by replacing the main draft with your copy, you would delete his changes. First, you probably should ask him, if he made any changes. Lets say he did in fact made changes. Now you probably have to somehow “merge” your copy of the draft with the main draft such that your colleague changes remain intact. This may seem easy at first sight, but it is not. To “merge” two copies, you need to know exactly where your colleague made the changes — the locations where paragraphs (or lines) were inserted, changed or even deleted. If your draft is large and your colleague had made several changes, there just is no easy way to do it.
We discussed these problems of “version control” and collaboration in context of writing a novel/story, but both of these are equally applicable to writing a computer software. During the development of a computer software, it is likely to go through several iterations, where portions of code may be inserted, replaced or even rolled back to a previous state, and often with multiple people working simultaneously.
Wouldn’t it be nice if there existed a software that could automatically save a copy of your work at different instances as well as perform merge between two versions of a file? That’s exactly what Git is.
In the next part, we will explore Git.

Anubhav Patel
Life doesn’t happen to you, it happens for you. 💯